시작하기
최근에 가장 많이 연구되고 있는 분야 중 하나가 바로 meta learning 입니다. meta learning 은 learning-to-learning 이라고도 불리고 있습니다. 이런 meta learning을 학습하는 방법 중 하나가 few-shot learning이라는 방법이 있습니다. 이 few-shot learning의 경우에는 classification과는 다른 방법으로 문제 및 데이터 샛을 정의 합니다. 저도 기존의 방법과 다른 형태다 보니 이해하는데 많은 시간이 소요 되었습니다. 이번 post에서는 few-shot learning에 대해 소개해드리고자 합니다.
Few-Shot Learning 이란
Few-Shot Learning이란 해당 용어가 말하는 대로 아주 적은 데이터르도 데이터의 특징을 식별할 수 있도록 하는 것입니다. 강아지의 경우를 예로 들면 사람은 한 장의 사진을 통해 강아지라는 Class의 Concept를 학습할 수 있습니다. 하지만 기존의 Deep learning의 경우에는 수백장 또는 수천장의 사진을 통해서 강아지라는 class의 특성을을 학습합니다.
이에 Network 학습시에도 class 별로 적은 양의 이미지를 보여주어서 네트워크를 학습 시키고 학습한 Network를 테스트 하는 것이 Few-Shot Learning의 수행 Process 입니다
Few-Shot Learning 관련 주요 용어
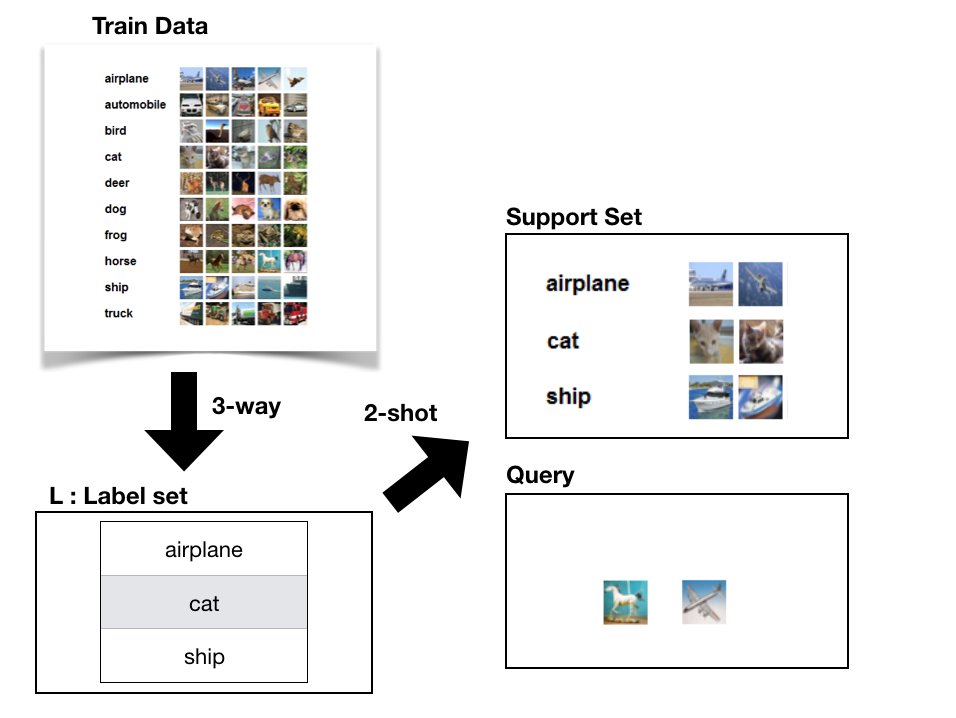
- n-way : 각 batch 별로 선택하는 label의 개수(N)
- K-Shot : 각 class별로 선택하는 Data 개수(K)
- support : 해당 batch에서 fine tuning을 위해 학습하는 셋
- query : 해당 batch에서 class를 예측해야 하는 데이터 셋
- episode : 한 epoch 당 수행하는 iteration 횟수
Few_Shot Data 생성 Process
[Step1] 가장 처음에는 Train/Test/(Valid) Set으로 데이터를 분할합니다. 이 방법은 기존에 알고리즘 학습을 위한 방법과 동일한 방법 입니다.

[Step2] 그 다음에는 각각 Dataset에서 N개의 Class에 대해 Sampling 작업을 수행 합니다.

[Step3] Sampling한 Label을 기준으로 하여 K개씩 데이터를 생성합니다. 이 때 2가지 Data Set(support/query)을 생성합니다. 이 때 support/query set은 서로 겹치지 않도록 합니다. 해당 데이터를 기준으로 support Set으로 모델을 학습을 먼저 수행하고, 모뎔에 대한 평가는 query로 판단합니다.
[주의사항]
- Few-Shot Learning 에서 기존 데이터 생성과의 가장 큰 차이점은 Sampling 수행 시 label의 index가 계속 바뀐다는 점입니다. 기존 모델 학습의 경우 CIFAR-10의 경우를 예로 든다고 하면 airplane = 0 ,…,truck = 9 로 label에 대한 index를 부여한다고 하면 이 label은 동일한 상태로 유지됩니다. 하지만 Few-Shot Learning의 경우에는 sampling 에 따라 airplane의 label이 0이 될 수도 있고 2가 될 수도 있습니다. 이 점이 기존 classification가 가장 차별된 점입니다. 하지만 sampling 돤 데이터 에서 support Set 과 query는 동일한 label을 유지합니다. 이래야만 모델이 어떤 데이터가 어떤 label을 의미하는지를 알고 예측할 수 있기 때문입니다.
지금까지 이야기한 내용을 한 장으로 압축한 그림의 형태가 다음과 같은 형태 입니다.

Reference
- https://www.slideshare.net/JisungDavidKim/oneshot-learning
- Ravi, Sachin and Larochelle, Hugo. Optimization as a model for few-shot learning. In International Conference on Learning Representations (ICLR), 2017. link